Zero Downtime Reindex in Elasticsearch
Why reindexing data in Elasticsearch?
Reindexing data is a common operation in working with Elasticsearch. When do we need to do it? Here are a few examples:
- Mapping change: when we change how data is analyzed and indexed. For example: changing a field's analyzer, changing an analyzer's definition, etc.
- Cluster upgrade or migration: Elasticsearch can only read indices created in the previous major version since 5.x. So if we want to upgrade our Elasticsearch that is several major versions behind, we have to resort to reindexing. For example, Elasticsearch support reindexing from a remote cluster.
Prior arts
We take a look at some available solutions to implement reindexing and analyze their pros and cons.
Elasticsearch's official Reindex API
Pros
- Easy: not much work to do since it's readily available.
- Fastest solution.
- Work for both: reindex within the same cluster or reindex from a remote cluster.
- Works well if we can stop indexing data for a while (to wait for the reindex process to finish).
Cons
- Hard to reason about consistency if writes still come to the old index during the reindex process.
- Meant for indices that must be "paused", so not really zero downtime.
- Only work with data that are already in Elasticsearch.
Index Alias Wizardry
In Elasticsearch, alias works as a pointer to one or multiple indices. Many have written about using it for zero downtime reindexing: using one alias or using two, one for read and one for write, etc.
Basically it works like this:
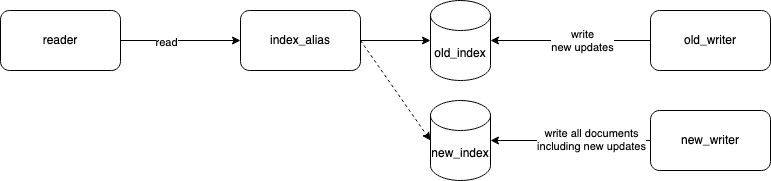
- Applications don't query the index directly, but through an alias
index_alias. - The alias points to the current index
current_index. - When we want to reindex data, we create a new index
new_index, probably with a new mapping. - Then we duplicate write: we write to both
current_indexandnew_indexat the same time. - Once
new_indexhas caught up withcurrent_index, we update the alias to point tonew_indexinstead ofcurrent_index. This can be done atomically. - If anything goes wrong, we just have to revert the final alias change.
Pros
- Straightforward.
- Revertible.
- Can include new fields from the source of truth outside of Elasticsearch.
Cons
- Only work within one Elasticsearch cluster.
- Requires quite some work, but handles only one use case.
- Most solutions don't mention how to keep data consistent between
current_indexandnew_index.
A generic solution
Above solutions are purely about data coming into Elasticsearch. However, not only data, but the applications that read and write these data are also important aspects to consider when we want to rollout a reindex operation.
For example, when we do a major mapping change, we might need to update application code to be able to query from the new index.
For upgrading Elasticsearch server version, we usually have to update the application code since the API might have changed. If we were to use a library like elastic4s, upgrading server means upgrading client library at the same time. To guarantee zero downtime, we need to be able to release application code and the new cluster version independently. How can we achieve that if we don't care about application code?
By incorporating these considerations, we can achieve a generic reindexing solution that works for all mentioned use cases, while having no downtime.
If we call this a recipe for reindexing, then here are the required ingredients:
- A data source that supports deterministic replay and multiple concurrent readers. Example: a Kafka topic, a change data capture stream, etc. Why? Because it allows us to have multiple independent writers/indexers that write/index the same set of data into different Elasticsearch indices in possibly different clusters.
- Decoupling between readers (applications that query from Elasticsearch) and writers (applications that write/index into Elasticsearch). Why? Because it allows us to separate their deployment (think microservices' independently deployable). As a result, we can scale and upgrade them independently. We will also see later that it allows us to easily upgrade Elasticsearch code from any arbitrary version.
- Writers that guarantee idempotent processing under at-least-once delivery. Why? Because combining this with the data source above, we can guarantee data consistency - all old and new indices will eventually have the same data.
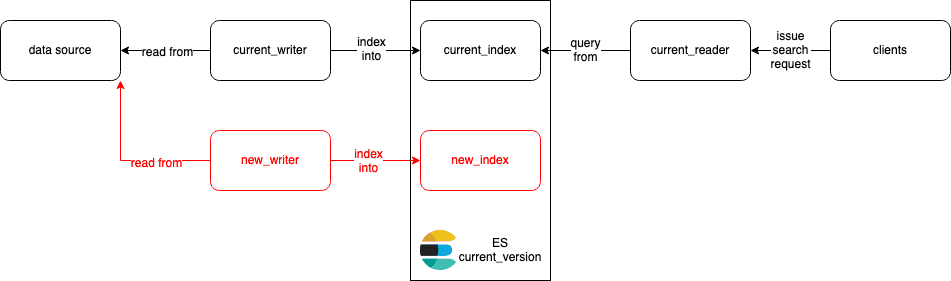
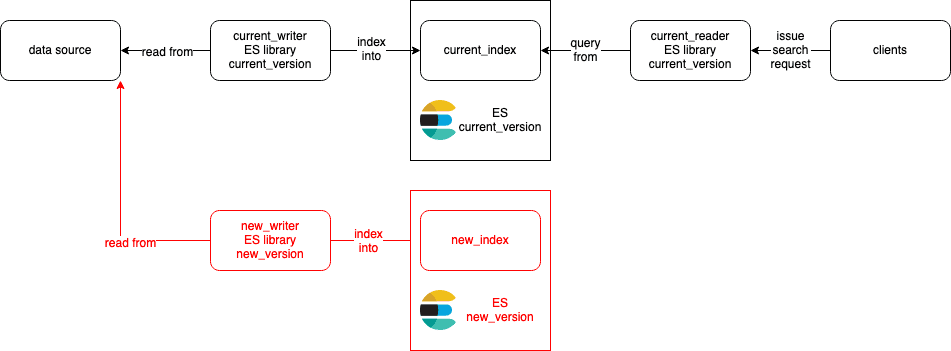
Here's how the most basic architecture looks like in normal operation:

- We have one writer/indexer
current_writerthat writes/indexes intocurrent_index. - A separate reader
current_readerquery from that index and forward the results to the clients. Alternatively, the reader can be a shared library embedded in the client applications.
Let's see how it evolves when we want to reindex data.
Example #1: reindex into the same cluster e.g when mapping changes
First, we create a new index new_index with the updated mapping. Then we deploy a new writer new_writer (either the same code as current_writer or newer code if needed) that writes data into this index.
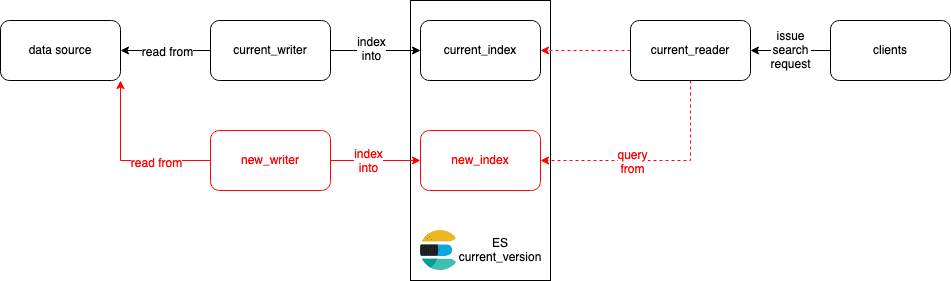
Once new_index has caught up with current_index, we redirect query requests from current_reader to new_index. This can be a configuration change on current_reader or simply an alias update on Elasticsearch.
If anything goes wrong, we just need to revert the final redirect change since current_index is still up to date.
For complex mapping changes, we might also need to update the reader code. In these cases, we can release a new version of reader - new_reader that queries directly from new_index. Once everything looks good, we redirect requests to new_reader instead of current_reader. Again, we just need to revert the last step if anything goes wrong.
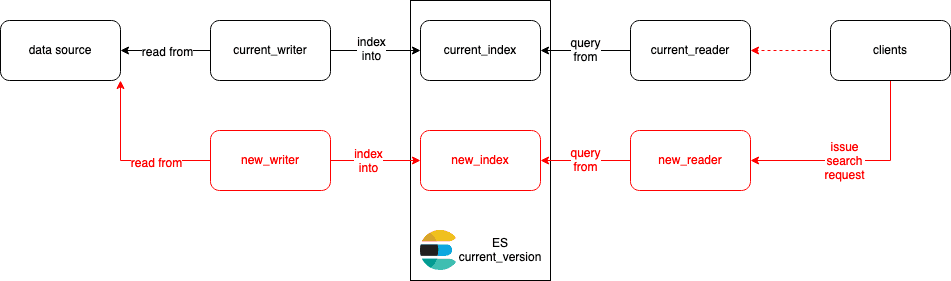
Example #2: reindex into another cluster e.g when upgrading or doing migration
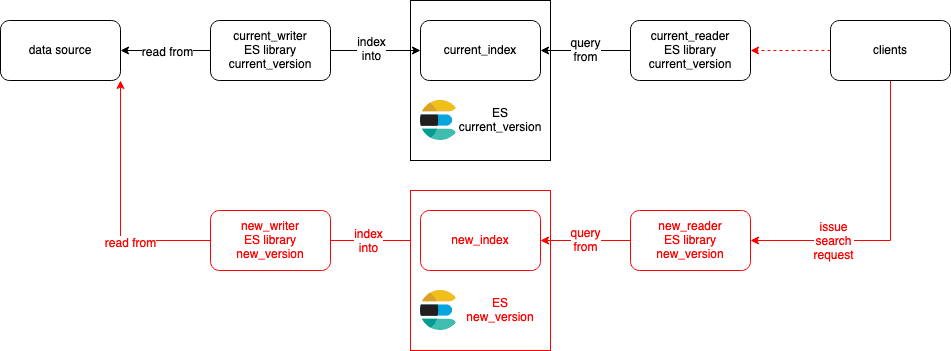
First, we create a new index new_index in the new cluster. Then we deploy a new writer new_writer that writes data into this index. new_writer's code has been updated with newer Elasticsearch client library to talk to the new cluster.
Next, similar to example #1, we release a new reader new_reader that query from new_index. new_reader's code has been updated with newer Elasticsearch client library. If things looks good, we switch clients to use new_reader. Again, this is fully revertible.
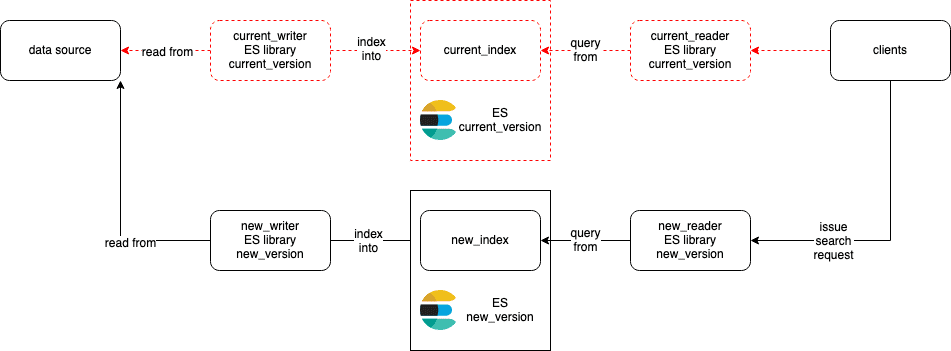
Final steps
Once we're happy with the result, we just need to retire those "current" indices, writers and readers. The diagram now looks exactly like the original.
Comparison to other solutions
Pros
- Not more complicated than using Index Alias.
- Generic solution that works for all use cases.
- All steps are incremental and revertible.
- Zero downtime. There is a clear plan for rolling back.
- Guarantee eventual consistency because of the requirements on the data source and writers.
- Freedom in deciding when the switch/redirect happens. If implemented properly, data is kept "in sync" in near real time.
Cons
- Not the most performance method. However, it's very flexible. For example, we can scale writers up if we want to speed up reindexing.
- It requires organizational maturity in CI/CD/Ops to automate the process successfully. With that said, manually doing it is also not that hard since the steps are all laid out.